【Python】 経済指標・財務諸表データ取得完全攻略
- 2021.05.26
- Python
Pythonを使った経済指標データの取得方法、取得元とともにまとめて記録しておく。
PythonライブラリのPandas-Datareaderを利用した取得が中心となるが、
Alpha Vantage APIを利用した財務諸表データ取得、EIAのAPIを使ったエネルギー関連情報の取得、DBnomicsからのデータ取得も併せて扱う。
これを全て使えば大抵のデータはそろうはず。
- 1. Pandas-Datareader概要
- 1.0.1. ・ Tiingo
- 1.0.2. ・ IEX
- 1.0.3. ・ Alpha Vantage
- 1.0.4. ・ Quandl
- 1.0.5. ・ FRED
- 1.0.6. ・ Kenneth French’s data library
- 1.0.7. ・ World Bank
- 1.0.8. ・ OECD
- 1.0.9. ・ Eurostat
- 1.0.10. ・ Thrift Savings Plan
- 1.0.11. ・ Nasdaq Trader symbol definitions
- 1.0.12. ・ Stooq
- 1.0.13. ・ MOEX
- 1.0.14. ・ Naver Finance
- 1.0.15. ・Econdb
- 1.0.16. ・ Yahoo Finance
- 2. Pandas-Datareaderの使い方
- 3. Alpha Vantage APIを使って財務諸表データを取得する方法
- 4. EIA APIを使ったデータ取得方法
- 5. DB・NOMICSからのデータ取得方法
- 6. まとめ
Pandas-Datareader概要
Pandas-Datareaderは様々な情報源から株価や為替、経済統計データを取得することができる、外部ライブラリです。
情報源(データ取得元)の一覧はこちら。
・ Tiingo
株価、投資信託、ETFの過去データを取得することができる。
利用するためにはAPIキーが必要になるため、無料登録が必要である。
・ IEX
ここも株価の過去データを取得することができる。
過去15年分のデータを取得可能。
15年よりも前のデータ取得が必要であれば、StooqやYahoo Finance、Alpha Vantageを利用することとなる。
・ Alpha Vantage
株式や為替(通貨ペア)のデータ取得が可能。
株式市場のセクターごとのパフォーマンスを取得することもでき、非常に便利。
また、pandas-datareaderでは取得できないが、APIを使って企業の財務諸表データを取得することもできる。
利用するためにAPIキーが必要になるため、無料登録が必要。
・ Quandl
様々な情報源から提供される経済指標データを取得することができる。
APIキー取得のために無料登録が必要であるが、無料で基本的なデータの取得は可能である。
(個人的には、データコードなどを探すのに使いにくい印象がある)
・ FRED
米国の経済データであれば、まずはFREDで探してみるのが一番
とにかく使いやすく、セントルイス連銀が提供しているデータベースであることから非常に信頼できるデータ取得元である。
ただし、米国以外の経済データに関しては手薄であるため、その他の情報源をあたる必要がある。
Pandas-Datareaderで利用するうえでは、APIキーは不要である。
・ Kenneth French’s data library
証券アナリスト資格などの勉強したことがある方にはおなじみのファーマ/フレンチの3ファクターモデルのデータなどが取得できる。
サイズファクターやバリューファクターなどのデータを参照したいのであれば、ここで確認することができる。
・ World Bank
世界銀行のデータベース。
新興国を含む世界各国の経済指標を網羅しており、複数の国の経済状況を比較分析したい場合には、非常に有用だろう。
しかし、データの更新が1年に1度だったりと更新頻度が少ないデータが多いため、短期的な経済の動きや最近起きたことがどのように経済に影響を及ぼしているのかを確認するためには不向きだと思われる。
・ OECD
先進国クラブとも呼ばれた国際組織のデータベース。
加盟国のデータを取得し比較するのには非常に便利。
しかし、途上国データの取得が十分にできるわけではないため、あくまえでも加盟国データを集めることを目的とした利用に適している。
(後程紹介するEcondbを使ったほうが便利)
・ Eurostat
欧州統計局のデータベース。
欧州諸国のデータを取得するのであれば、ここで大抵のものは見つかるだろう。
(Econdbを介してEurostatのデータを取得するほうが便利)
・ Thrift Savings Plan
投資信託のデータ取得ができるようである。
(使ったことがないので詳細不明)
・ Nasdaq Trader symbol definitions
・ Stooq
株式、債券、株式指数、為替など多くのマーケット・データの取得ができる。
APIキーなしで利用でき、非常に使い勝手がよい。
・ MOEX
ロシアの証券取引所。
ロシア株のデータが必要であれば、いいのかもしれない。
使ったことはない。
・ Naver Finance
KOSPIの銘柄など、韓国の株式データが欲しい方には有用だと思われる。
こちらも利用経験なし。
・Econdb
世界銀行やOECD、IMFなどの国際機関や各国統計局のデータをひとまとめにしたデータベース。
使ってみたところ、OECDやEurostatなどのデータもここを介して取得したほうが取得しやすく、本当に使いやすい。
また、IMFのデータはPandas-DatareaderではEcondbを介してでなければとれないし、トルコや南アフリカなどの統計局のデータを取得するもでき、新興国・途上国の経済指標を取得するのにも便利に使える。
PandasでCSVファイルURLをスクレイプすることなども与わせれば、興味深いタイムリーなデータの取得もできる。
APIキーも不要。
・ Yahoo Finance
Pandas-DatareaderのDocumentには記載されなくなっているが、Yahoo Financeのデータも取得ができる。
株式指数、株式、債券利回りなど多くのデータを取得することができる。
Stooqと同じくAPIキーなしで利用ができる非常に素晴らしいデータ取得元である。
Pandas-Datareaderの使い方
まず、Pandas-Datareaderは外部ライブラリのため、インストールする必要がある。pip installで取得すればよい。
私はconda環境を使っているため、同じようにanacondaを利用している方はこれでインストールできるはず。
conda install -c anaconda pandas-datareader私がよく使うAlpha Vantage、FRED、World Bank、Stooq、Econdb、Yahoo Financeからデータ具体的な使い方を順に説明する。
Alpha Vantageからのデータ取得方法
・Alpha Vantage 株式データの取得方法
まずは株式データを取得する。
その際の使い方は以下の通り。
import pandas_datareader.data as web # pandas-datareaderのインポート
df = web.DataReader('ティッカー','エンドポイント',start='hoge',end='hoge',api_key='hoge')
# ティッカーは['hoge1','hoge2']のようにリストにして複数指定できるエンドポイントは、下記のなかから一つ選択する。
- av-intraday
- av-daily
- av-daily-adjusted
- av-weekly
- av-weekly-adjusted
- av-monthly
- av-monthly-adjusted
startやendは指定しなくてもよい。
startのみ指定することで、任意の時点から現在までのデータを取得することができる。
別の書き方として、
df = web.get_data_alphavantage('ticker' api_key='hoge')↑のように書いてもデイリーデータを取得することができる。
・ Alpha Vantage セクターパフォーマンスの取得方法
セクターパフォーマンスの取得は一行だけです。
df = web.get_sector_performance_av(api_key='hoge')取得できるデータは、[‘RT’, ‘1D’, ‘5D’, ‘1M’, ‘3M’, ‘YTD’, ‘1Y’, ‘3Y’, ‘5Y’, ’10Y’]の期間のパフォーマンスです。
データの取得は非常に簡単だが、パフォーマンスデータには’%’が付いた文字列として取得されるため、棒グラフにするときには若干の処理が必要。
df = df[['1D','5D','1M','3M']].applymap(lambda x:x.strip('%')).astype(float)
# 必要な列を指定、その後'%'を取り除き、floatに変換
import cufflinks # plotlyでデータフレームをグラフにするためのライブラリ
fig = df.iplot(asFigure=True, kind='bar') # グラフ作成
fig.show()・ Alpha Vantage 為替データの取得方法
以下の書き方いずれでも取得が可能。
df = web.get_data_alphavantage('USDJPY', api_key='hoge')
df = web.DataReader('USDJPY', 'av-daily', api_key='hoge')
df = web.DataReader('USD/JPY', av-forex-daily, api_key='hoge')エンドポイントにav-forex-hogeを使う場合には、XXX/XXXのように’/’を入れる必要があるので注意。
また、一番目、二番目の方法だと、Volumeの列が無駄にできてしまう(Volume列のデータは全てゼロになっているため意味のない列)
Alpha Vantage APIを使った財務諸表データの取得はPandas-Datareaderとは別であるため、後述することにする。
FREDからのデータ取得方法
FREDでは米国の経済統計データの取得が中心となる。
pandas-datareaderを使ったFREDからのデータ取得方法はAlpha Vantageを使う場合とほとんど変わらない。
import pandas_datareader.data as web
df = web.DataReader('datacode', 'fred', start='hoge', end='hoge')
# データコードはリスト形式で複数指定可能
# startとendは指定しなくてもよい。これだけでdataframe形式で経済統計データが取得できる。
データコードは経済データページのデータ名の隣か、URLの一番最後の部分となっている。
US CPIの場合、下記URLのCPIAUCSLAがデータコード。
https://fred.stlouisfed.org/series/CPIAUCSL
World Bankのデータ取得方法
from pandas_datareader import wb
df = wb.download(indicator='hoge', country='hoge', start='hoge', end='hoge')
# indicator、countryはリストで複数指定可能
# countryはISOの3桁か2桁のカントリーコードで指定する使用例を示します。
df = wb.download(indicator='SP.POP.TOTL',counry=['JPN','USA'],start='2018',end='2019')これを実行すると下記のようなスタックされたDataframeの結果が返ってくる。
SP.POP.TOTL
country year
Japan 2020 NaN
2019 126264931.0
2018 126529100.0
United States 2020 NaN
2019 328239523.0
2018 326687501.0そこで見やすく、可視化する場合にも扱いやすいように加工するとよい。
df = df.unstack()↓
SP.POP.TOTL
year 2018 2019
country
Japan 126529100 126264931
United States 326687501 328239523Stooqからのデータ取得方法
Stooqからのでーた取得も株式のtickerを指定するだけで取得できる。
また、株式指数や国債利回りの取得も可能
ただし、中には取得できないものもあり、通貨ペアのticker symbolを指定してもデータの取得が取得できなかったりする。
下にS&P 500とAAPL、米国10年債利回りの取得例を示す。
結果は、Close、High、Low、Volumeのデータがかえってくる。
今回はCloseデータのみを選択する。
df = web.DataReader(['^SPX','AAPL','10USY.B'],'stooq',start='2000-01-01')
df = df['Close'] # 一行目のサイドに['CLose']をつけてもよいだろう↓
Symbols ^SPX AAPL 10USY.B
2000-01-03 1455.22 0.8608 6.548
2000-01-04 1399.42 0.7881 6.485
2000-01-05 1402.11 0.7998 6.599
2000-01-06 1403.45 0.7306 6.549
2000-01-07 1441.47 0.7655 6.504
... ... ... ...
2021-02-10 3909.88 135.3900 1.124
2021-02-11 3916.38 135.1300 1.167
2021-02-12 3934.83 135.3700 1.212
2021-02-16 3932.59 133.1900 1.311
2021-02-17 3931.33 130.8400 1.274米国株式以外にも日本株や日本のETFデータなども取得することができるため、株式や株式指数、ETFのデータ取得には非常に使える。
Econdbからのデータ取得方法
90以上の公的統計機関のデータ取得ができる。
df = web.DataReader('ticker=hoge', 'econdb', start='hoge', end='hoge)
# 複数のデータを指定して取得する場合、
df = web.DataReader('ticker=hoge1,hoge2', 'econdb')上記のように複数のデータを指定して取得する場合の書き方がFREDなどとは異なっているため注意が必要。
データのticker IDは各データの適当なデータをクリックすればすぐに確認できる。
例えばEurostatからある国のGDPデータを取得する場合、Econdb 欧州諸国GDPの適当なデータをクリックすれば、

このいうな形でデータのTicker IDが簡単に確認できる。
また、データを一つ一つ選択するのではなく、datasetから必要なデータをまとめて取得することでもできる。
web.DataReader('dataset=NAMQ_10_GDP&GEO=[AL,AT,BE,BA,BG,HR,CY,CZ,DK,EE,EA19,FI,FR,DE,EL,HU,IS,IE,IT,XK,LV,LT,LU,MT,ME,NL,MK,NO,PL,PT,RO,RS,SK,SI,ES,SE,CH,TR,UK]&NA_ITEM=[B1GQ]&S_ADJ=[SCA]&UNIT=[CLV10_MNAC]', 'econdb')
# start、endを使っての指定ももちろん可能 データセットのticker IDはURLがdataset/tickerIDとなっているため、それを使えばよい。
また、下記のようにExportからPandas Python3を選択するとコードを作成してくれる。(fromやto、hとv(列や行の指定)は消して使ってえばよい)
あらかじめデータを左のフィルターで指定してからコード作成すればよい。
データの取得元によって、指定する方法が微妙に違うので、Exportで作成したPythonコードを参考にして、任意の形に変更を加えて使うのがいいと思う。
また、上記のコードでdatasetでまとめてデータを取得すると、列名がMultiIndexで渡されるため、可視化する場合には編集が必要になると思われます。
例えばEurostatからdatasetを上記のコードで取得した場合の列名の構造を確認すると、
names=[‘Frequency’, ‘Unit of measure’, ‘Seasonal adjustment’, ‘National accounts indicator (ESA10)’, ‘Geopolitical entity (reporting)’]
このようになっているため、各タプルの5番目を抜き出せばよい。
df.columns = [i[4] for i in df.columns]
# [df.columns[i][4] for i in range(len(df.columns))でも可上述した通り、データ取得元によってdatasetでのデータ指定方法が異なるため、いくつか例を張っておくことにする。
# IMFの指定国CPIデータを取得
df_imf = web.DataReader('dataset=IMF_CPI&FREQ=[M]&INDICATOR=[PCPI_PC_CP_A_PT]&REF_AREA=[AF,AL,DZ,AO]', 'econdb')
# OECDの消費者信頼感データ
df_oecd = web.DataReader('dataset=OE_KEI&FREQUENCY=[M]&LOCATION=[AUS,AUT]&SUBJECT=[CSCICP02]', 'econdb')
# OECDから実質GDPの前年同期比のデータを取得
web.DataReader('dataset=OE_KEI&FREQUENCY=[Q]&MEASURE=[GY]&LOCATION=[AUS,BRA,CAN,CHN,EU28,FRA,DEU,GRC,ESP,ITA,IND,IDN,ISR,JPN,MEX,NLD,NZL,NOR,OECD,RUS,SWE,TUR,GBR,USA]&SUBJECT=[NAEXKP01]', 'econdb',start=start_date)国の指定がLOCATIONだったり、REF_AREAだったりと違いがあり、また、指定できる項目にも違いがあるため、それぞれ確認する必要があるが、覚えてしまえば非常に便利。
いずれも列名はMultiIndexで渡される。必要に応じて編集してください。
また、データは各期間の開始時点が日付としてふられているため、分析で使う場合には.resample(‘q’,label=’right’).last()をつけるなどして、日付を変更したほうがいいかと思います。
Yahoo Financeからのデータ取得
Stooqからの取得とコードはほとんど同じ。
ただ、Yahoo Financeだと為替データもしっかり取得できる。
Stooqで取得したデータに加えて、USDJPYのデータをあわせて取得してみる。
結果は、Adj Close、Close、High、Low、Volumeのデータが返ってくる。
df = web.DataReader(['^SPX','AAPL','^TNX','JPY=X'],'yahoo',start='2000-01-01')これでUSDJPYのデータも取得できる。
通貨ペアのデータを取得する場合、通貨コード=Xとする場合、USDをベースカレンシー、選択した通貨をクウォートカレンシー(プライスカレンシー)としたデータが取得される。
そのため、USDよりも通常前にくる、EUR、GBP、AUD、NZDの対USDデータを取得する場合には、’XXXUSD=X’のように通貨コードを選択する。
Alpha Vantage APIを使って財務諸表データを取得する方法
使うAPIリンクはこちら。
url_PL = 'https://www.alphavantage.co/query?function=INCOME_STATEMENT&symbol={}&apikey={}'.format(symbol,api_key)
url_BS = 'https://www.alphavantage.co/query?function=BALANCE_SHEET&symbol={}&apikey={}'.format(symbol,api_key)
url_CF = 'https://www.alphavantage.co/query?function=CASH_FLOW&symbol={}&apikey={}'.format(symbol,api_key)
url_EPS = 'https://www.alphavantage.co/query?function=EARNINGS&symbol={}&apikey={}'.format(symbol,api_key)上から、損益計算書、貸借対照表、キャッシュフローステートメント、EPSのデータ取得用のURLである。
.format()で株価のsymbolとapi_keyを指定するようにしてあるが、リンク内にそのまま書き込んでももちろん使える。
結果はJSONで帰ってくるので、Pythonでdataframeに加工する。
またデータは文字列になっているので若干手を加えたほうが使いやすくなる。
下記のもので損益計算書、貸借対照表、キャッシュフローステートメントのいずれもdataframeにすることができる。
def FR(url):
r = requests.get(url)
r = r.json()
data = r['quarterlyReports']
df = pd.json_normalize(data)
df.set_index('fiscalDateEnding',drop=True,inplace=True)
df.index = pd.to_datetime(df.index)
df = df.replace('None',0).drop('reportedCurrency',axis=1).astype(float).sort_index()
return df_PLEPSデータをdataframeにするのであれば、これでいいかと思います。
def EPS(url):
r = requests.get(url)
r = r.json()
data = r['quarterlyEarnings']
df_EPS = pd.json_normalize(data)
df_EPS.set_index('fiscalDateEnding',drop=True,inplace=True)
df_EPS.index = pd.to_datetime(df_EPS.index)
df_EPS = df_EPS.replace('None',0)
df_EPS[df_EPS.columns[1:]].astype(float).sort_index()
return df_EPSEIA APIを使ったデータ取得方法
データ頻度がWeeklyなのかMonthlyなのかでAPIを利用したときにかえってくる結果が異なるが、どちらにも対応できるようにPythonで関数定義をする。
import requests
import pandas as pd
def eia(url_list):
dft = pd.DataFrame()
for url in url_list:
r = requests.get(url)
r = r.json()
data = r['series'][0]['data']
df = pd.DataFrame(data,columns=['period',r['series'][0]['name']]).set_index('period')
try:
df.index = pd.to_datetime(df.index)
except:
df.index = pd.to_datetime(df.index,format='%Y%m',errors='coerce')
df.sort_index(inplace=True)
dft = pd.concat([dft,df],axis=1)
return dft上記のeia()関数にAPIのURL、複数URLから成るリストを渡せば、それだけで指定したデータをEIAから取得、dataframeとして扱うことができる。
DBnomicsを介してEIAのデータを取得することができるが、DBnomicsは更新のされていないデータも中には見られるため(南アフリカの統計局データは、一部OECDデータ、OAGのデータなど)、EIAのデータに関してもできることなら、EIAから直接取得したほうが確実だと思われる。
DB・NOMICSからのデータ取得方法
DB・NOMICSはEcondbと同じように世界中の統計局や情報提供機関のデータを取得しやすいようにひとまとめにしたデータベースを提供している。
各データをPythonのdataframeとして取得する場合には、CSVファイルのURLをpandasで読み込むのが一番簡単だろう。
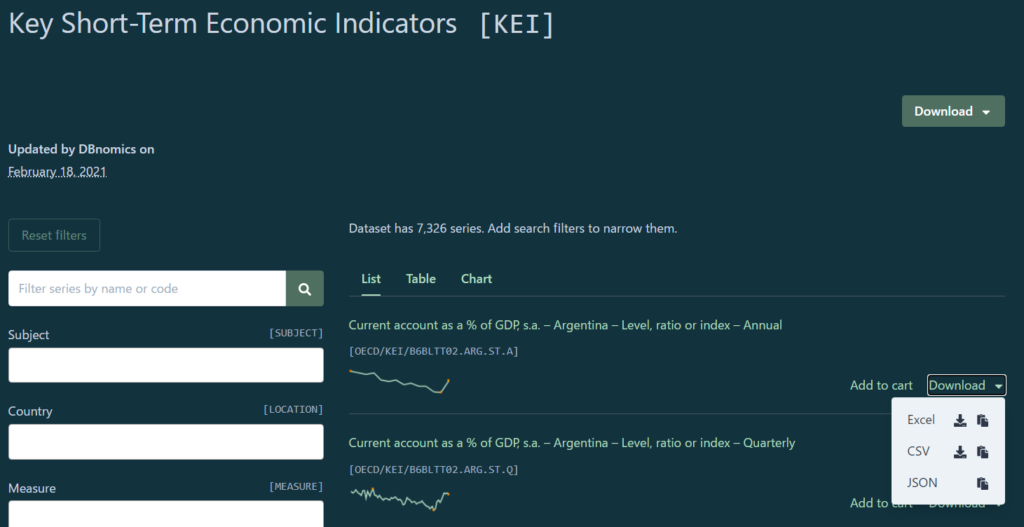
この画僧はOECDのKey Short-Term Economic Indicatorsのデータ一覧ページだが、各データの右下にある「Download」をクリックすれば、CVSファイルのリンクをコピーできる。
あとは、pd.read_csv()で読み込むだけ。
import pandas as pd
df = pd.read_csv('URL',index_col=0)また、左にある検索フィルターを使って指定したデータを一度に取得することもできる。
その場合には、ページ右上にある「Download」からCSVやJSONなど任意のURLを取得すればよい。
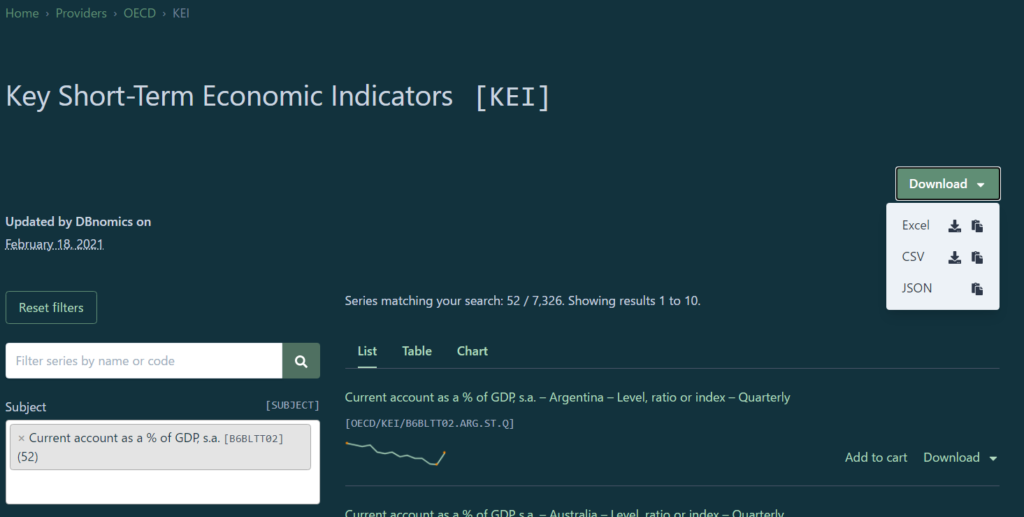
ただし、CSVで一括取得すると、列名がやたら長く使いにくい形で取得される。
経常収支GDP比の四半期毎のデータを取得した場合、
Current account as a % of GDP, s.a. – Argentina – Level, ratio or index – Quarterly (OECD/KEI/B6BLTT02.ARG.ST.Q)
が一列目の列名となる(MultiIndexではなく通常のIndex形式)
そのため、JSON形式で取得して自動的に国名を列名として使うように関数定義しておいたほうが便利だと思う。
import requests
import pandas as pd
import pycountry as pc # ISO国コードを国名に変換するためのライブラリ
def db(url):
r = requests.get(url)
r = r.json()
dft=pd.DataFrame()
for i in range(len(r['series']['docs'])):
periods = r['series']['docs'][i]['period']
values = r['series']['docs'][i]['value']
try:
try:
col = [r['series']['docs'][i]['dimensions']['geo']]
except:
col = [r['series']['docs'][i]['dimensions']['LOCATION']]
except:
col = [r['series']['docs'][i]['dimensions']['region']]
df=pd.DataFrame(values,index=periods,columns=col)
dft=pd.concat([dft,df],axis=1)
dft.columns = [pc.countries.get(alpha_2=j).name if len(j)==2 and j not in ['EA','EL','UK','uk'] else 'Euro area' if j == 'EA' else 'Greece' if j == 'EL' else j for j in dft.columns]
dft.sort_index(inplace=True)
return dft列名の指定が長ったらしくなっているが、EUやギリシャのISOコードが特殊だったりするため、その処理を指定している。
ISO国コードを国名に変換するためにpycountryという外部ライブラリを使用している。
上記関数でOECD以外の多くの国際機関のデータも取得できると思うが、国名がgeoで指定できるのかLOCATIONで指定できるのかなどJSONの内容に違いがあるため、確認して利用する必要がありそう。
まとめ
以上でpandas-datareader、Alpha Vantageからの財務諸表データ、EIA、DBnomicsからのデータ取得ができるようになったと思います。
公的統計機関の提供する経済データはたいてい取得できるのではないかと思います。
特定セクターや途上国データなどより専門的なものは取得できないものも少なくはないと思いますが、それらに関しては別途APIや最悪スクレイプするなどして取得するより他ないでしょう。
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/297078ff.733fd8f7.29707900.f492f002/?me_id=1213310&item_id=19842087&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F8901%2F9784873118901.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

-
前の記事
記事がありません
-
次の記事

【Python】statsmodelsで自己相関を計算・可視化 2021.06.02