【Python】pandasを使ったデータ処理入門-為替データで実践
- 2022.11.23
- Programming Python
Pythonでデータの取り扱いをする方ならほとんどの方が使うことになるであろうpandasでのデータ処理について、実際の為替データを使いながら基本をまとめていきたいと思う。
為替データ取得・実践データの準備
# まずはデータ取得に使うライブラリをimport
import pandas_datareader.data as web
import pandas as pd
# 今回はSt.Louis連銀の管理するデータベースFREDからEURUSDとUSDJPYのデータを取得する
# ['DEXUSEU','DEXJPUS']が取得対象データ意味する。
df = web.DataReader(['DEXUSEU','DEXJPUS'],'fred',start='2010-01-01')
# それぞれのデータが表示される列の名前をわかりやすく変更しておく
df.columns = ['EURUSD','USDJPY']
"""
取得データを表示すると以下のような形になっている。
EURUSD USDJPY
DATE
2010-01-01 NaN NaN
2010-01-04 1.4419 92.55
2010-01-05 1.4402 91.48
2010-01-06 1.4404 92.53
2010-01-07 1.4314 93.31
... ... ...
2022-11-14 1.0337 140.43
2022-11-15 1.0372 139.36
2022-11-16 1.0395 139.59
2022-11-17 1.0341 140.45
2022-11-18 1.0349 140.03
"""データの基礎的な加工・整形等
時系列データの再標本化・リサンプリング
時系列データを取得した場合、日次データを取り扱いたいのか、月次データを取り扱いたいのか、はたまた四半期ごとなのか年次なのかと目的によって取り扱いたいデータの間隔・観察頻度は異なってくる。
また、四半期ごとに発表されるGDPと毎月発表される鉱工業生産、日次で観察される為替データをあわせて確認する場合には、観察頻度の少ないデータの欠損部分を補完するか分析に使用するデータ四半期末のものを用いるといった何らかの調整が必要になってくるだろう。
また、ある一定間隔での各期間における最大値や最小値といった基本統計量を知りたいと考えることもあるだろう。
そこで、resample()を使った再標本化や各期間における基礎統計量の取得方法してみる。
resampleで指定するパラメータ
- rule : リサンプリング後の間隔、何分割するのかといったルールを定める
下記の主要なものを抑えておけば良いだろう。- D : 日次 3Dとして3日ごととすることもできる。(もちろんその他の日数も)
- B : 営業日
- W : 週次
- M : 月次
- Q : 四半期
- Y : 年次
- BM : 月末営業日
- label : right または left
インデックスの値を区間終了時とする場合にはright、開始とする場合にはleftを選択。
( ‘M’, ‘A’, ‘Q’, ‘BM’, ‘BA’, ‘BQ’, ‘W’はデフォルトでrightが指定される)
例として、日次データを月次データにリサイクリングする場合にleftを選ぶと1/1~1/31の値はリサイクリング後のインデックス値12/31の情報として取り込まれる。
例として取得したデータから1月から2月1日までのデータを選び出し、それをlabel=’left’とlabel=’right’とで月次データにダウンリサンプリングしてみる。
df.head(22)
"""
頭から22行のデータは下記の通り。
EURUSD USDJPY
DATE
2010-01-01 NaN NaN
2010-01-04 1.4419 92.55
2010-01-05 1.4402 91.48
2010-01-06 1.4404 92.53
2010-01-07 1.4314 93.31
2010-01-08 1.4357 92.70
2010-01-11 1.4536 91.90
2010-01-12 1.4523 90.95
2010-01-13 1.4492 91.38
2010-01-14 1.4478 91.03
2010-01-15 1.4376 90.79
2010-01-18 NaN NaN
2010-01-19 1.4269 91.13
2010-01-20 1.4094 91.23
2010-01-21 1.4106 90.25
2010-01-22 1.4154 90.07
2010-01-25 1.4146 90.12
2010-01-26 1.4063 89.63
2010-01-27 1.4053 89.41
2010-01-28 1.3993 90.08
2010-01-29 1.3870 90.38
2010-02-01 1.3904 90.80
"""
# 上記のデータをlabel='left'でリサンプリングする。
df.resample('m',label='left').last()
"""
label='left'とした場合の結果。
EURUSD USDJPY
DATE
2009-12-31 1.3870 90.38
2010-01-31 1.3904 90.80
"""
# label = 'right'でリサンプリングする。
df.resample('m',label='right').last()
"""
label='left'とした場合の結果。
EURUSD USDJPY
DATE
2010-01-31 1.3870 90.38
2010-02-28 1.3904 90.80
"""- Closed : right または left
こちらは終了時点、開始時点どちらのデータを含めるかを決めるものだが、labelと同じものを指定しておけばよい。(というよりもlabelと同じにする)
# 上記で取得したデータを日時データから月次データに変換する
dfm = df.resample('m',label='right').last().dropna()
# dropna()は欠損値のある行を削除するリサンプリング結果の統計量確認
上述したリサンプリング後の結果、各区間の基本的な統計量を確認する。
まずは、日次データを月次データ(各月の最終データ)に変換したデータフレームの基本統計量を確認する。これは単にリサンプル前のデータに対して行う基本統計量の確認と変わらない。
dfm.dscribe() # 基本統計量の一覧表示
"""
EURUSD USDJPY
count 155.000000 155.000000
mean 1.207405 104.546065
std 0.114605 15.177173
min 0.978300 76.340000
25% 1.115850 95.880000
50% 1.182200 107.840000
75% 1.307400 112.530000
max 1.482100 148.630000
"""次にリンプル時に各区間における統計量を取得する。
これは単にresample()の後ろに.std()や.max()をつければ、任意の統計量を取得することができる。
また、aggregate([‘mean’,’max’,’min’,’std’]) などとすれば、統計量を一括指定して確認できる。
import numpy as npとしてうえで、aggregate([np.mean, max, min, np.std])でも同じ結果が得られる。
(aggregateの代わりにaggを使うことも可能)
df.resample('m',label='right').std() # 標準偏差
df.resample('m',label='right').mean() # 平均
df.resample('m',label='right').aggregate(['mean','std']) # 平均と標準偏差
"""
aggregateで一括した場合の結果。
EURUSD USDJPY
mean std mean std
DATE
2010-01-31 1.426574 0.019981 91.101053 1.103408
2010-02-28 1.367995 0.013562 90.139474 0.893510
2010-03-31 1.357004 0.012244 90.716087 1.344899
2010-04-30 1.341682 0.013327 93.452727 0.675920
2010-05-31 1.256315 0.027239 91.973000 1.520617
... ... ... ... ...
2022-07-31 1.016825 0.008463 136.709000 1.449660
2022-08-31 1.012878 0.012325 135.283478 2.155573
2022-09-30 0.989881 0.014634 143.284286 1.345498
2022-10-31 0.985295 0.009379 147.051500 1.812530
2022-11-30 1.011485 0.022661 143.879231 3.590802
"""欠損値の取扱いと補間方法
分析前に欠損値をどのように扱うのか、どういった方法で補間を行うのかを決めることは重要である。
欠損値の削除
dropna()を使えば、いずれかの行の値に欠損値が含まれる場合には欠損値のある行を削除できる。
引数にinplace=Trueをしていすれば、欠損値のある行を削除したデータフレームで変数を更新する。
dropna()は行のいずれかの要素に
df.dropna(inplace=True) # dfを欠損値のある行を削除したデータフレームに更新欠損値の補間
- .ffill() : 欠損値の前のデータで補間
- .bfill() : 欠損値の後ろのデータで補間
- .interpolate() : 線形補間やスプライン補間などの補間を行うことができる
引数にmethod=’spline’でスプライン補間を行う。デフォルトではmethod=’linear’
他にも’polynomial’や’nearest’などの指定が可能である。
splineやpolynomialを指定した場合には、それらの次数を引数にorder=指定次数 として指定する必要がある。
データの変化率、移動統計
次にデータの変化率や移動統計(指定したデータ数での平均や標準偏差等を求める)を扱う。
変化率、差分
まずは様々な変化率の計算から行っていきたいと思う。
変化率の計算にはpct_change()も用いる。
- periods : 何データ前のデータを基準点とするのかを指定
- freq : 基準点とする日時を何日前、何ヵ月前といった形で指定する
periodsがデータフレームの何データ前を基準点とするのかを指定するのに対して、freqは何日前、何ヵ月前といった日時を使って基準点を指定する。 - fill_method : 欠損値の補間方法を指定できる。
ffill:欠損値の前のデータで補間 bfill:欠損値の後ろのデータで補間
fill_methodでは線形補間のようなことはできない。より複雑な補間を行うには予めデータフレームに対して.interpolate()を使って補間を行う。
# 各データの20行前のデータと比較した変化率
df.pct_change(20)
# 365日前からの変化率
df.pct_change(freq='365D')差分計算
差分の計算は.diffを使って行う。
引数にはperiodsで何データ前との差を計算するのかのみ指定でき、pct_changeでできるようなfreqでの指定はできない。
移動統計
移動統計は移動平均に代表されるように、指定したデータ数の平均値等の基礎統計量を計算して取り扱うことができる。
データ数で指定することもできるし、window=’50D’ のようにして、過去50日のデータを指定して移動統計を計算することもできる。ただし、週数や月数では指定できないようである。
日数でwindowを指定した場合、それに満たない部分(データ数で指定した場合にはNaNになる部分)は含められる最大のデータから計算される点には注意が必要である。
まずはUSDJPYの移動平均を計算し、可視化してみる。
import matplotlib.pyplot as plt
df_usdjpy = pd.DataFrame(df['USDJPY']).dropna() # 欠損値は削除
# SMA 20Dという列名で20日移動平均を追加
df_usdjpy['SMA 20D'] = df_usdjpy.rolling(window=20).mean()
df_usdjpy.dropna(inplace=True)
df_usdjpy.plot() # 折れ線グラフの作成
plt.show() # 作成したグラフを表示グラフは下記のように表示される。
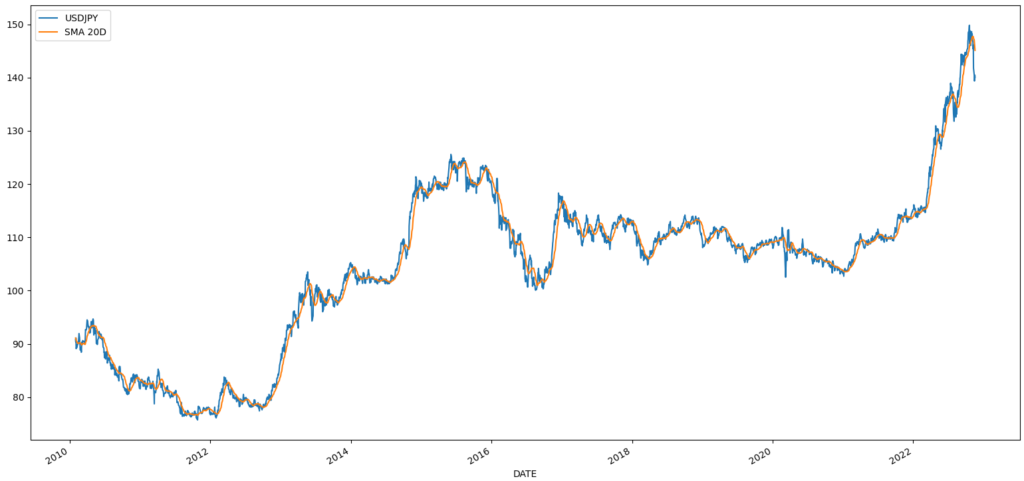
移動統計は他にもminやmax、median、stdなどの基本統計量は一通り計算することができる。
わざわざこの方法で作る必要はないとは思うが、移動平均や標準偏差といった移動統計を計算してプロットすればボリンジャーバンドとして可視化することも可能である。
次にUSDJPYとEURUSDの移動相関係数を計算してみる。
df.dropna(inplace=True)
df_corr = df['USDJPY'].rolling(window=250).corr(1/df['EURUSD']) # 1年を250営業日と仮定
# ドルに対しての動きをみるために1/df['EURUSD']との相関係数を求める
df_corr.dropna().plot()
plt.show()相関係数をグラフは以下のようになる。
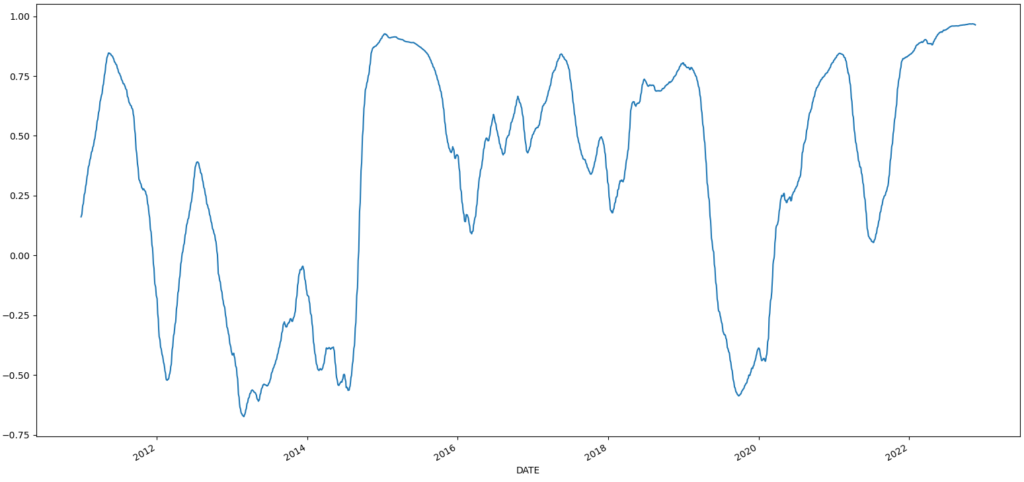
-
前の記事

【米国雇用統計】2022年10月 米国労働市場の詳細確認 2022.11.05
-
次の記事
【米国雇用統計】2022年11月 米国労働市場の詳細確認 2022.12.03