【Python】時系列データ分析と基本的な統計モデルの作成方法
Pythonを使った統計モデルの作成や時系列データの性質の確認などについて、基礎的なものをまとめていきたいと思う。
(Pythonの内容や結果のプロットなど全て作成できているわけではないが、時間があるときに更新していこうと思っている)
指数平滑モデル
指数平滑モデルの中で最も基礎的且つシンプルなモデルが以下のものである。
後述するトレンドや季節要因を含む複雑な指数平滑モデルとは違い、トレンド要素や季節要因を含まない変数に対するモデルとして使用するのに適している。
指数平滑モデルは、過去の値の持つ将来の予測値を説明する力は時間経過とともに指数的に逓減するとの考え方を反映している。
Yt+1 = αYt + α(1-α)Yt-1 + α(1-α)2Yt-2…
Pythonを使った単純指数平滑モデルの作成
Pythonを使ってトレンドも季節性も持たない最もシンプルな指数平滑モデルを作成してみる。
今回は米国の消費者物価指数を取得してきて、それに対して指数平滑法を使ってみる。
import pandas_datareader.data as web
import matplotlib.pyplot as plt
from statsmodels.tsa.holtwinters import SimpleExpSmoothing as se
df = web.DataReader('CPIAUCSL','fred',start='2010-01-01',end='2022-10-01').resample('m',label='right').last() # 消費者物価指数を取得し、indexの日付を月末に指定
se_model = se(df) # モデルの作成
se_fit = se_model.fit()
preds = se_fit.forecast(12) # 12ヵ月先までの予測。out-of-sample-forecastを返す。
df_preds = pd.concat([se_fit.fittedvalues,preds]) # se_fit.fittedvaluesはサンプル内予測(in-sample-forecast)を返す
dft = pd.concat(df,df_preds],axis=1)
dft.columns = ['CPI', 'preds']
dft.plot()
plt.show()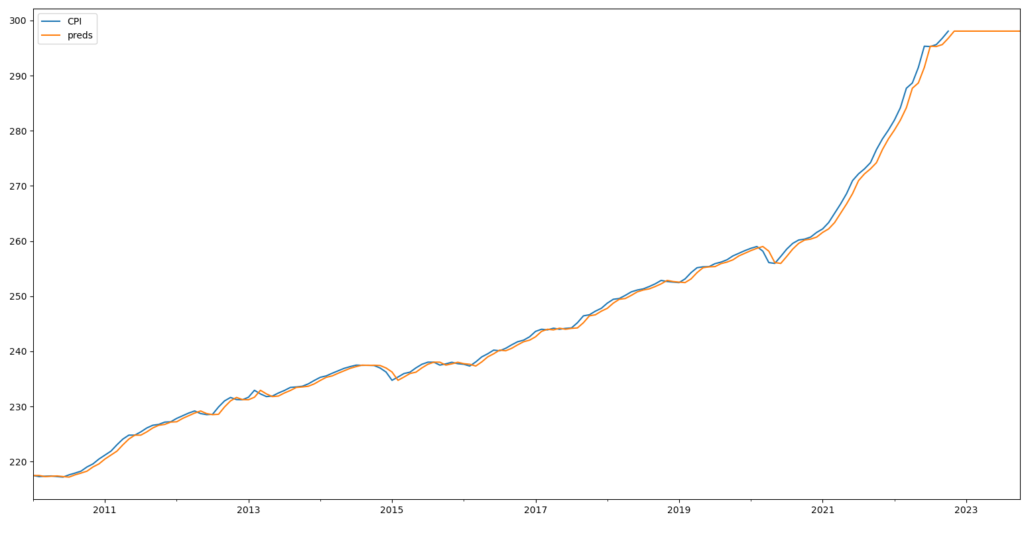
Holt’s linear trend
レベルのみを含む指数平滑モデルにトレンド要素を追加したモデル。
継続的な上昇または下降トレンドをたどることを想定したモデルとなる。
Yt+i = ℓt + i・bt
ℓt = αYt + (1-α)(ℓt-1+bt-1)
bt = β(ℓt-ℓt-1) + (1-β)bt-1
上記式に”dampens”パラメーターを追加し、将来のどこかの時点においてフラットになるようなモデルもある。
Yt+i|t = ℓt + (φ+φ2+…+φi)bt
ℓt = αYt + (1-α)(ℓt-1+φbt-1)
bt = β(ℓt-ℓt-1) + (1-β)φ・bt-1
φが1ならdampensがないものとまったく同じだが、1よりも小さければトレンドを失速させフラットな状態に向かわせる。
Holt-Winter’s 指数平滑モデル
Holt’s線形モデルに季節要因を追加したモデル。パラメーターはα、β、γ。
Yt+i|t = ℓt + (φ+φ2+…+φi)bt + St+i-m(k+1)
ℓt = α(Yt-St-m) + (1-α)(ℓt-1+φbt-1)
bt = β(ℓt-ℓt-1) + (1-β)φ・bt-1
St = γ(Yt – ℓt-1 – bt-1) + (1-γ)St-m
PythonでのHolt-Winter’s指数平滑モデルの実施
消費者物価指数のデータを用いて実際に作成してみる。
statsmodels.tsa.holtwintersからExponentialSmoothingをインポートして指数平滑モデルを作成する。
時系列データ以外に引数にしているするものは下記の通り
(addはadditive、mulはmultiplicativeを意味する)
- trend : ‘add’, ‘mul’, Noneから選択
- damped_trend : True or Falseで選択。トレンドの減速有無
- seasonal:季節要因。’add’, ‘mul’, Noneから選択
- seasonal_periods:季節要因の周期
実践してみようと思うが、ここでは訓練データとテストデータの分割や複数のパラメーターの組み合わせを試してのモデル評価は行わない。
from statsmodels.tsa.holtwinters import ExponentialSmoothing as es
# 前述した単純指数平滑モデル作成に用いたデータを使ってモデルを作成する
es_model = es(df_es, trend='add', damped_trend=False, seasonal='mul', seasonal_periods=12)
es_fit = es_model.fit()
preds = es_model.predict(params=es_fit.params,start='2010-01-31',end='2023-10-31')
df_preds = pd.DataFrame(index=pd.date_range(start='2010-01-31',end='2023-10-31',freq='m'),data=preds,columns=['preds'])
dft = pd.concat([df,df_preds],axis=1)ARIMAモデル
ARIMAモデルの前にARIMAモデルの基礎となるモデルの考え方と数式だけ示しておく。
ARモデル
ARモデル(自己回帰モデル)は被説明変数の過去の値に説明力があるものと考え、ある変数の過去の値から現在や将来の値を予測する。
一次AR(p)モデル(AR(1))を数式にすると以下のようになる。
Yt = α + φ1Yt-1 + εt
MAモデル
MAモデル(移動平均モデル)はある変数がその期待値を中心にして推移するものと仮定し、現在の値は過去の撹乱項から説明できると考えたモデルである。
一次MA(q)モデル(MA(1))の計算式は以下のようになる。
Yt = μ + εt + θ1εt-1
この数式からわかるように、期待値は一定であることから、Ytは現在の撹乱項と過去の撹乱項から決定されることとなる。
MAモデルでout-of-sample-forecast(サンプル外予測)を行う場合、サンプルの平均値でフラットな予測結果を返すこととなる。
ARIMAモデル
上記ARモデルとMAモデルとを組み合わせたがモデルがARMAモデルである。
ARMAモデルは定常性を前提としているため、非定常過程に従う変数に対してはそのまま使用することができない。
一方でモデルを差分系列への変換を取込んでARMAモデルを一般化したモデルであるARIMAモデルは非定常性を持つ変数に対しても階差を指定して使用することが可能である。
更に季節要因への対応するために複雑化させたSARIMAモデルや外因性変数を取り込んだ拡張したモデル(ARIMAX、SARIMAX)まで様々なものがある。
Python用いたARIMAモデルの作成
statsmodels.tsa.arima.modelからARIMAをインポートしてモデルを作成する。
ARIMA(p,d,q)のパラメーターを決める必要がある。
p:自己回帰モデルのAR(p)にあたる部分についてのパラメーター指定
d:時系列データを定常的になるのに必要な階差を指定
q:移動平均モデルにおけるMA(q)の部分に対応するパラメーター指定
ARIMA(1,0,0)であればAR(1)モデルを意味し、ARIMA(0,0,1)はMA(1)モデルを意味する。
ARIMA(1,1,0)であれば原系列データの1階差分を取った階差系列に対するAR(1)となる。
SARIMAモデルを作成するには、SARIMA(p,d,q)(P,D,Q)mと季節要因分のパラメーター指定が増える。
これらはすべてstatsmodels.tsa.arima.model.ARIMAがあれば、引数にorder=(p,d,q), seasonal_order=(P,D,Q,M)のような形で指定のパラメーターを渡すことでARモデル、MAモデル、ARMAモデル、ARIMAモデル、SARIMAモデルのいずれも構築が可能である。
また、外因性変数を引数として含めることでARIMAXやSARIMAXなどのモデルにすることも可能である。
(ちなみにstatsmodels.tsa.arima.model.ARIMA以外にも、statsmodels.tsa.statespace.sarimax.SARIMAXまたはstatsmodels.tsa.api.SARIMAXをインポートして、そちらを使ってARIMAやSARIMAモデルを設計することもできる。
ARIMAがOLS・伝統的な方法による一方でSARIMAXは状態空間モデルによってモデルの構築が行われるとされており、モデル構築の方法が異なる。詳細はこちらのドキュメントを確認いただきたい。)
下記ではARIMAを使ってモデル作成を行ってみる。
指定する主なパラメーター一覧は以下のものになる。
- endog:時系列データの実績値
- order:(p,d,q)を指定。
- seasonal_order:(P,D,Q,M)を指定。デフォルトでは(0,0,0,0)
- trend:確定的トレンドをコントロールするパラメーター。指定は任意。
- ‘n’:確定的トレンドなし
- ‘c’:コンスタント
- ‘t’:線形トレンド
- ‘ct’:コンスタント及び線形トレンド
実際にいくつかパラメーター別に作成してみる。
(最後のSARIMAのみAICを使ったグリッドサーチで当てはまりが良さそうなパラメーターを指定したが他は適当にパラメーターを選択)
from statsmodels.tsa.arima.model import ARIMA
# 前述した単純指数平滑モデル作成に用いたデータを使ってモデルを作成する
# ARIMA(1,1,0)モデルの作成
ar_model = ARIMA(df,order=(1,1,0),seasonal_order=(0,0,0,0)) # seasonal_orderはデフォルトで(0,0,0,0)のため指定しなくてもよい
ar_fit = ar_model.fit()
ar_preds = ar_fit.predict(start='2010-02-28',end='2023-10-31')
# ARIMA(1,1,1)
arima_model = ARIMA(df,order=(1,1,1))
arima_fit = arima_model.fit()
arima_preds = arima_fit.predict(start='2010-02-28',end='2023-10-31')
# SARIMA(1,2,2)(1,0,1,12)
sarima_model = ARIMA(df,order=(1,2,2),seasonal_order=(1,0,1,12))
sarima_fit = sarima_model.fit()
sarima_preds = sarima_fit.predict(start='2010-01-31',end='2023-10-31')
dft = pd.concat([df,ar_preds,arima_preds,sarima_preds],axis=1)
dft.drop(dft.index[[0,1]],inplace=True) # SARIMAの結果が非常にはずれた値が出るため始めの部分を削除
dft.columns = ['CPI','ARIMA(1,1,0)','ARIMA(1,1,1)','SARIMA(1,2,2)(1,0,1,12)']ARIMAモデルの予測について
予測結果を作成する方法はいくつかあるため、整理しておきたいと思う。
ARIMAモデルを作成し、そのモデルに対してfit()メソッドを使用するとARIMAResultsを返す。そのARIMAResultsのプロパティやメソッドを使用して予測を行う。
(上記の例でいえば、sarima_fitに対して下記メソッド等を利用すればよい)
- .fittedvalues : in-sample forecasts
- .forecast(steps=n):サンプルの最終データからn期先までのout-of-sample forecasts
- .predict(start=hoge,end=hoge):予測期間応じたin-sample, out-of-sample forecasts
endを指定しない場合はサンプルの最終データまでの期間のin-sample forecasts - .get_forecast(n):予測レンジを含むout-of-sample forecasts
- .get_prediction():予測レンジを含むin-sample, out-of-sample forecasts
.get_forecastと.get_predictionの結果に対して、.summary_frame()メソッドを使うことで予測結果及びレンジをdataframeとして取得できる。
また、seやse_meanといったプロパティを持っている。
GARCHモデル
ARCHモデル、GARCHモデルはボラティリティの自己相関関係についてモデル化してボラティリティの推移を予測しようというものである。
Yt = μt + ut = μt + σtεt , εi~N(0,1)
ARCH : σ2t = ω + α1u2t-1 + … + αnu2t-n
GARCH : σ2t = ω + α1u2t-1 + … + αnu2t-n + β1σ2t-1 + … + βmσ2t-m
GARCH(1,1) : σ2t = ω + α1u2t-1 + β1σ2t-1
マルコフ転換モデル(MSモデル)
好況時と不況時でのリスク資産の動きなど、置かれている前提状況によって動きに特徴が出るような変数をモデル化することができる。状態によって離散的にモデルのパラメーターが変化する点は閾値モデルと同じだが、状態として観測できない変数を含めることができる点で閾値モデルと異なる柔軟性がある。
マルコフ転換モデル(マルコフ転換自己回帰モデル)は計算式は以下のとおりである。
Yt = φ0(St) + φ1(St)Yt-1 …. + σ(St)εt
Stが状態を示しており、その状態に従う関数φを係数としてモデルを構成する。
マルコフモデルでは状態Stがマルコフ連鎖に従うものとする。
マルコフ連鎖において状態Stは1時点前のSt-1のみを条件とする条件付確率に従う。
Stが1~nのいずれかの値をとるとした場合、St=j となる確率は、下記の形で表される。
P(St=j | St-1=i)
モデルパラメーターの推定・評価
pythonで統計モデルを作成する場合には一定範囲内でのパラメーターの組み合わせを全て下記の情報量基準のAICやBICによって評価し、最も優れているものを使用するという方法を取ることができる。
(AICやBICが最も低いものが必ずしも最も良い当てはまりになるとも断言できないため、いくつかの候補を試してみたほうが安全ではある)
代表的な情報量基準
IC
IC = -2L(θ) + p(T)k
θは最尤法で推定した最大対数尤度。
kは最尤推定で推定したパラメーターの数、Tは推定に使ったパラメーターの数である。
p(T)はTに従う関数であり、p(T)kはプラスしているのは、パラメーター数を増やせば関係のないものを加えたとしても最尤度は上昇するため、パラメーターを増やことに対しての費用を課すようなイメージである。
AIC
AIC = -2L(θ) + 2k
AICではp(T) = 2 としてモデルを複雑化することによるマイナス評価部分を定めたものになる。
BIC
BIC = -2L(θ) + log(T)k
p(T) = log(T) と推定に使ったパラメーター数の対数を使ってマイナス評価部分を定める評価方法である。
基本的にはAICやBICを使って様々な統計モデルを評価することができるが、AICとBICどちらが優れた評価方法であるとは一概に言うことはできず、どちらの結果も確認しつつ、自身で判断するしかない。
時系列データの性質等テスト
単位根・定常性検定
Dickey-Fuller検定
下記式(定数(ドリフト)を含まない形を用いることや、非確率的時間トレンドを加えた形もある)に関してρが1、又は、二つ目の式の形においてδが0であれば、Yが単位根過程であることを意味することとなる。
それを帰無仮説を棄却できるか否かで判断する。
ΔYt = α + (ρ-1)Yt-1 + εt
(ρ-1)をδとすると、
ΔYt = α + δYt-1 + εt
定数や非確率的時間トレンド(deterministic time trend)の有無にADFの式を一覧は下記の通りとなる。
- 線形のみ:ΔYt = δYt-1 + εt
- 定数含む:ΔYt = α + δYt-1 + εt
- 定数及び非確率的時間トレンドを含む:ΔYt = α + βt + δYt-1 + εt
Dickey-Fuller検定を拡張したAugumented Dickey-Fuller (ADF))検定が広く使われている。
ΔYt = α + βt + γYt-1 + δ1・ΔYt-1 +…+ δp-1・ΔYt-p+1 + εt
こちらの式では、γ=0 であれば、単位根であることを意味するため、γ=0とする帰無仮説を棄却できれば単位根ではないと考えられることとなる。
PythonでのDickey-Fuller検定
まずは単純な実行方法からみてみる。
from statsmodels.tsa.stattools import adfuller as adf
result = adf(x_series) # 検定対象としてseries型のデータを渡す
print('p-value : ', result[1])
# 検定結果のp値を表示。有意水準を5%とするなら0.05以下になることを確認すればよい。回帰式の形を指定することもできる。
パラメーターに、regression = hoge のような形で書きリストから任意のものを指定する。
- “nc” : 定数なし、トレンドなし
- “c” : 定数のみ。デフォルトではこの形が設定されている。
- “ct” : 定数及びトレンド
- “ctt” : 定数、線形及び二次非確率的時間トレンド
ラグの長さを選択する方法は、autolag = hoge の形で下記のものから選択できる。
- “AIC” : デフォルトではAICが設定されている
- “BIC”
- “t-stat”
経済統計を使ったテスト
SP500の月間終値を使ってADFによる検定を試してみる。
import pandas_datareader.data as web
df = web.DataReader('SP500','fred',start='2015-01-01').resample('m',label='right').last()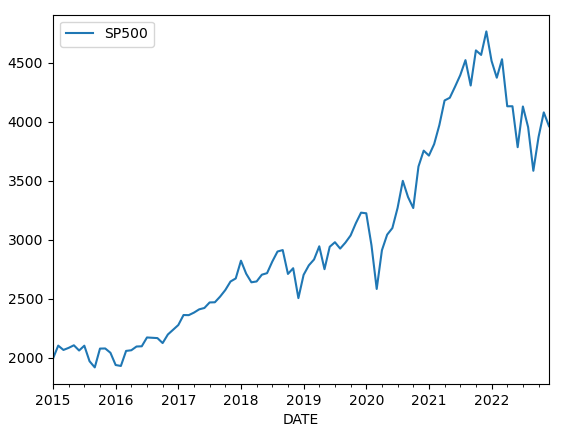
SP500はは見ての通りそのままの形では定常性を期待できる形にはない。
そこで、前月との差をとってみることとする。
dfd = df.diff(1).dropna()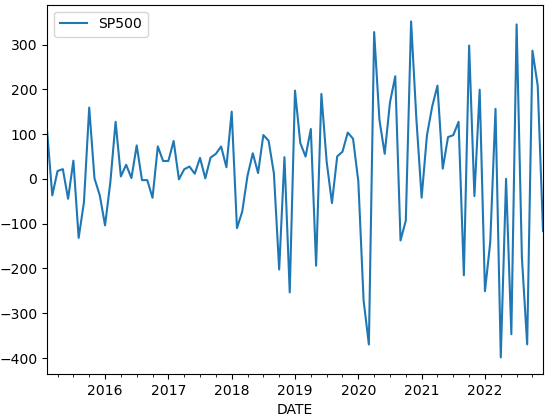
この形を使ってADF検定に当てはめると、結果は以下の通りとなり、有意水準5%と考えれば、帰無仮説を棄却できず定常性があるとはいえないこととなる。
result1 = adf(dfd)
print(result1[1].round(5)) # 0.06369
result2 = adf(dfd,regression='ct')
print(result2[1].round(5)) # 0.22141
result3 = adf(dfd,regression='ctt')
print(result3[1].round(5)) # 0.30735
ちなみに2度差分とって検定してみると定常性がみられた。
dfd2 = df.diff(2).dropna()
result4 = adf(dfd,regression='c')
print(result4[1].round(5)) # 0.01044
Granger因果性検定
Granger因果性検定は、被説明変数Yの統計モデル作成にあたり、Yの過去の値のみからなる回帰もでると、説明変数XとYの過去のデータからなる回帰モデルとを比較し、説明変数Xを加えたモデルのほうが当てはまりがよい場合に、被説明変数Yと説明変数Xの間に因果関係があるものとする検定である。
Y及びXの定常過程である場合には、それらを使って検定を行うが、定常的でない場合には差分系列を使って検定を行う。
PythonでのGranger因果性検定の実施
statsmodelsからgrangercousalitytestsをインポートして使用する。
パラメーターとして渡す時系列データの二列目の時系列データを説明変数、一列目の時系列データを被説明変数として検定が行われる。
また、検定に用いるラグの最大値を引数として渡す必要がある。
引数にverbose=True を追加すると細かい結果を表示することができる。
from statsmodels.tsa.stattools import grangercausalitytests as gct
df = web.DataReader(['DEXJPUS','DGS10'],'fred',start='2010-01-01').dropna()
dff = df.diff(1).dropna()
results = gct(dff,maxlag=5,verbose=True)あとは結果からF-scoreとP-valueを確認してP-valueが十分に低いようであれば、グレンジャー因果性が認められ、YとXの間に因果関係があるものと考えることができる。(グレンジャー因果性が必ずしも因果関係があることを保証するものではない)
-
前の記事

【米国雇用統計】2022年11月 米国労働市場の詳細確認 2022.12.03
-
次の記事

2023年の日銀の政策転換と方向を考える 2022.12.31